1. 선택 정렬
시간복잡도: O(n^2)
제자리 정렬 알고리즘 중 하나
0번째에 올 원소, 1번째에 올 원소... 이렇게 선택해 가져오는 정렬
전체중에서 가장 "작은 것" 을 계속 반복해서 비교해야 함
1. 최소값을 찾는다
2. 그 값을 맨 앞에 위치한 값과 교체한다
3. 맨 처음 위치를 뺀 나머지 리스트를 같은 방법으로 교체

'다음'에 있는 원소들 중 '가장 작은 거'
작은 순서대로 바뀐다.
비교횟수: n-1, n-2, n-3 ... 2, 1번
n번이n/2번 있는 것 n * n/2 = 1/2n^2 -> 시간복잡도가 O(n^2)
-이중 선택 정렬: 한 번의 탐색에서 최솟값과 최댓값을 같이 찾는 방법. 탐색 횟수가 절반으로 줄어듬
2. 삽입 정렬
시간복잡도: O(n^2)
정렬되어 있는 부분에 새로운 원소를 삽입
두 번째 원소부터 삽입정렬을 시작하는데, 삽입하는 원소의 왼쪽이 '정렬된 리스트'

(왼쪽) 정렬되어 있는 리스트
(오른쪽) 정렬되지 않은 리스트
빨강: 삽입할 원소
삽입할 원소와 정렬되어 있는 리스트를 비교한 뒤 끼워넣는다.
하지만 정렬되어 있는 경우 (자신의 왼쪽을)한 번씩밖에 비교하지 않아 복잡도는 O(n)
3. 버블 정렬
시간복잡도: O(n^2)
느리지만 코드가 단순하다
두 개의 인덱스를 잡아 그 둘끼리 비교해 정렬한다.
정렬이 잘못되어 있으면 위치를 바꾸고, 아니라면 다음 원소와 비교한다.
한 바퀴를 다 돌아야만 한 (적어도)원소의 완벽한 위치가 정렬된다.(가장 큰 값)
-원소의 이동이 거품이 수면으로 올라오는 듯한 모습을 보이기 때문에 '버블 정렬'
양방향으로 했을 시, > 칵테일 정렬

변화가 없을때 모두 정렬된 것으로 친다.(여러번 반복해야 함)
4. 합병 정렬
시간복잡도:O(nlogn)
분할 정복 방식으로 설계된 알고리즘
두 개의 배열로 계속 쪼개고 바닥을 찍으면 두 개의 배열을 합쳐 나가면서 정렬한다.
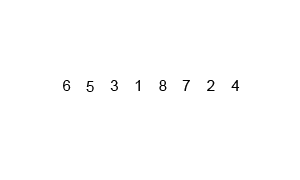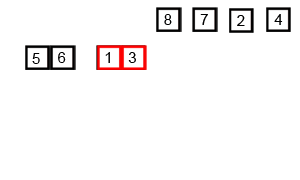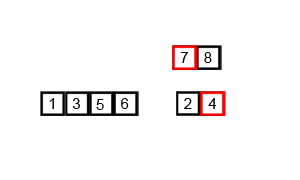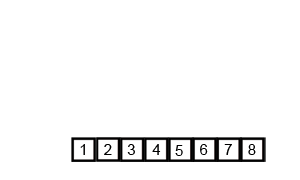
5. 퀵 정렬
시간복잡도: O(nlogn)
*내부 루프가 컴퓨터에서 효율적으로 작동하도록 설계되었고
매 단계마다 적어도 1개의 원소가 자기 자리를 찾기 때문에 다른 O(nlogn) 알고리즘에 비해 빠르게 동작한다.
분할 정복 방식으로 설계되었다.
다른 원소의 비교만으로 정렬을 수행하는 '비교 정렬'에 속함
기준이 되는 값(피벗)을 하나 설정(보통 가운데) 하고 그 값을 기준으로 2개의 부분리스트로 분활한 뒤 정렬한다.
이후 이를 반복한다
1. 피벗 앞에는 피벗보다 값이 작은 원소들이 오고, 뒤에는 큰 원소들이 오도록 리스트를 둘로 나눈다(분할)
2. 분할된 리스트에 대해 재귀적으로 이 과정을 반복한다.
*같은 값을 정렬할 경우 초기 순서와 달라질 수 있기 때문에 '불안정 정렬'에 속한다.

6. 쉘 정렬
시간복잡도: O(n^2) (최악의 경우)
평균은 갭 시퀀스에 따라 달라진다고...
(그러나 평균적인 경우 O(n^1.5)
가장 오래된 정렬 알고리즘
초기리스트가 '거의 정렬' 되어 있을 경우 효율적
한 번에 한 요소의 위치만 결정되기 때문에 비효율적인 면이 있다
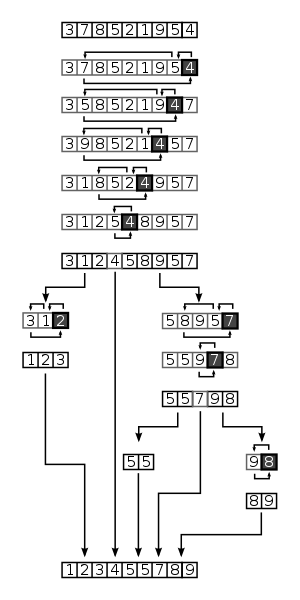
간격을 정해서 나눈 후 먼 간격에서 정렬. 원소들이 한 번에 더 먼 거리를 이동할 수 있게 됨
원거리 위치 교환으로 자리를 찾을 가능성이 높아진다.
1. 데이터를 듬성듬성 나누어 삽입 정렬한다
2. 다시 나누어 삽입정렬한다.

7. 히프 정렬
시간복잡도: O(nlogn)
힙 트리/최소 힙 트리를 구성해 정렬
(힙: 완전이진트리)

1. 완전 이진트리를 구성한다.
2. 최대 힙을 구성한다.(부모가 자식보다 큰 트리)
3. 가장 큰 수와 작은 수를 교환한다
4. 2~3 반

1. 이진 탐색 트리를 만든다
2. 아래가 위보다 크면 이동
그러니까 '맨 위 노드'를 '가장 큰 노드'로 만드는 것을 목표로 한다.
3. 그다음에 배열에 다시 담는다.
'가장 큰 노드'를 맨 끝에 옮겨서 정렬.
그럼 트리의 맨 위는 '작은 노드'가 되기 때문에 다시 정렬을 함
정렬할 게 없으면 그게 최대인것
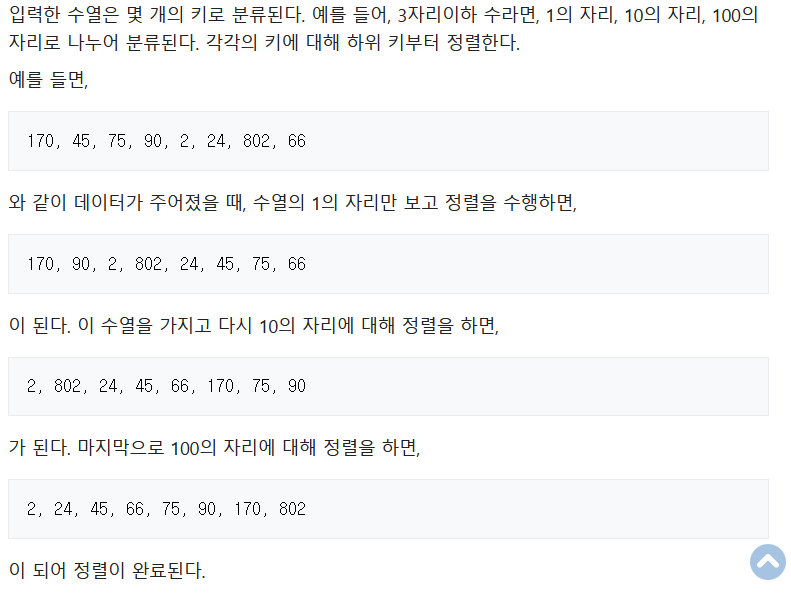
8. 기수 정렬
시간복잡도: O(k+n) *n은 기수의 도메인
원소를 비교하지 않고 정렬 수행
정수, 낱말 등 다양한 자료를 정렬할 수 있다.
예: 숫자
1의자리 정렬 > 2의자리 정렬 > 3의자리 정렬...
으로 정렬이 이루어짐
참고자료
https://hsp1116.tistory.com/33
기본 정렬 알고리즘(Sorting Algoritm) 요약 정리 (선택, 삽입, 버블, 합병, 퀵) v1.1
정렬 알고리즘은 n개의 숫자가 입력으로 주어졌을 때, 이를 사용자가 지정한 기준에 맞게 정렬하여 출력하는 알고리즘이다.예를 들어 n개의 숫자가 저장되어있는 배열을, 오름차순의 조건으로
hsp1116.tistory.com
https://ko.wikipedia.org/wiki/%EC%84%A0%ED%83%9D_%EC%A0%95%EB%A0%AC
'2022 스터디 > 알고리즘 스터디[2022]' 카테고리의 다른 글
| [Greedy] 체육복 (0) | 2022.05.16 |
|---|---|
| [DFS/BFS] 타겟 넘버 (0) | 2022.05.02 |
| [해시] 완주하지 못한 선수 (0) | 2022.04.11 |